... well, maybe that's a bit of an exaggeration, but it's certainly much more intelligent than before. Look:
 |
| Code completion in CSS |
 |
| ... bash |
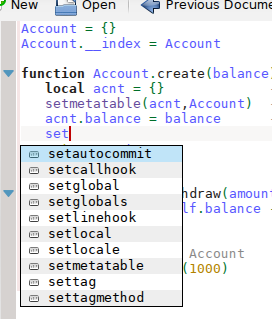 |
| ... Lua |
 |
| ... PHP |
|
 |
| even Gnuplot! |
 |
| Note how this one has a different set of possible items for the same query, respecting the context. |
 |
| Even Mathematica ;) This image shows a problem which still needs to be fixed: in case-insensitive languages, all completion suggestions are lowercased (which is not technically wrong of course, but a bit ugly). It's easy to fix but simply not done yet. |
There's unexpected profit from this in quite some areas, even KDevelop: for example, through this we now get code completion for all keywords in doxygen comments:
 |
| Completion for doxygen keywords inside a doxygen comment |
Of course, those only appear inside actual doxygen, and not C++. When the cursor is in C++ code, it shows the C++ keywords instead (but they will not be very visible in KDevelop, since they're sorted below KDevelop's suggestions, which are better).
How does this work?
Short answer: magic! Correct answer: it uses the highlighting files. For highlighting, kate has a list of possible keywords for languages listed in highlighting files (
/usr/share/apps/katepart/snytax/$language,xml). Those keywords are even context-sensitive: you will notice that e.g. the PHP highlighter does not highlight PHP function names inside comments or strings. So, the highlighting engine needs to know which keywords are valid at which position. Those are precisely the keywords which are suggested in the list.
What now?
Now that we have this feature, I think we can make more out of it in quite some cases. Especially, I want to invite you to have a look at your favourite language, and make sure all keywords / builtin functions / etc. are actually listed. Because of this feature, it might make sense to list keywords for languages where they are not terribly helpful for highlighting; a prominent example would be HTML, where currently the highlighter is totally generic and does not actually look at e.g. the tag names (thus, there's no completion). If you'd fix that by actually listing all valid HTML tag names, you'd (1) get better highlighting, e.g. you can mark undefined elements (think typos) as errors and (2) completion for free with that.
Another thing which can be improved is the context sensitivity. Some languages already do this rather well, but many languages will higlight keywords also in places where it'd be easy to detect that the keyword does not make sense there. That doesn't matter that much for highlighting only, because generally users write code which makes sense, but still -- if you can detect it, both consumers of the highlighting data (the actual highlighting, and the completion engine) gain something from it. So, extra motivation for making things more exact! ;)
I'm sure we can do more cool stuff with this. If you can come up with a good idea -- tell me, I'm happy to talk about it.